

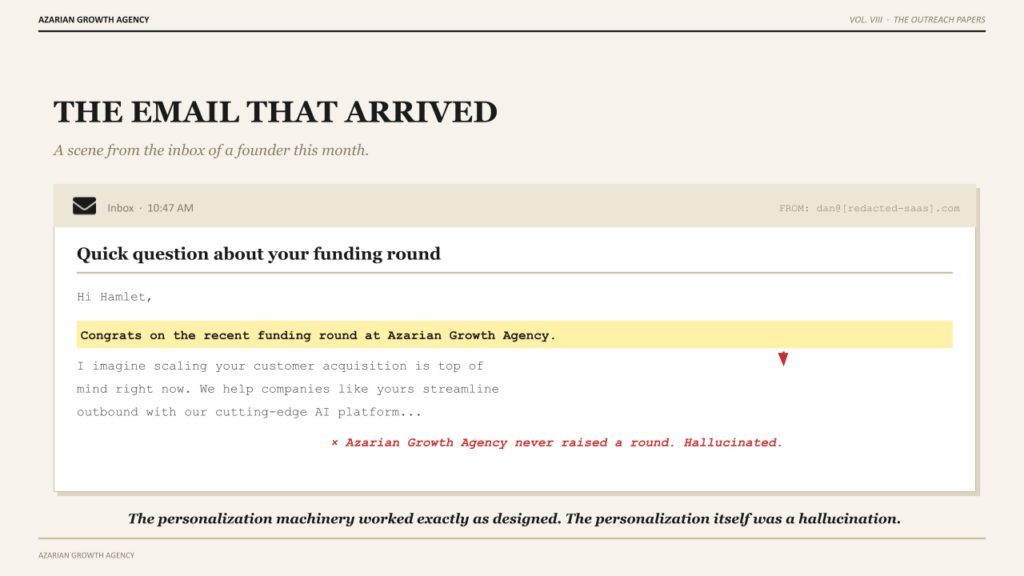
The worst email I received this month opened with a sentence I want to share with you because it is so close to good and so far from real. It read: Hi Hamlet, congrats on the recent funding round at Azarian Growth Agency. I imagine scaling your customer acquisition is top of mind right now. The rest of the email pitched me a contact data tool I have no use for.
Azarian Growth Agency did not raise a funding round. Azarian Growth Agency is a services business that does not take outside capital. The sender’s agent had pulled some unverified signal from some database, fed it into a template that had been built to sound personal, and shipped the result without a single human eye on the output. The personalization machinery had worked exactly as designed. The personalization itself was a hallucination wrapped in a friendly opener.
This is what most teams mean when they say AI personalized outreach. Mail-merge tokens with one or two enrichment fields, dropped into a template that pretends to know the buyer. The buyer sees through it on the first line. Reply rates are collapsing on this approach across the entire B2B category, and the deliverability story is getting worse every quarter as the providers learn to detect the pattern. The industry calls this personalization. The buyer calls it noise.
I want to spend this post on what personalization actually means when an agent writes the message, because the gap between the two definitions is large enough to be the difference between a working outbound motion and a broken one. The agent is a tool. The tool only does what the architecture above it tells it to do. The architecture above it, at most companies, is still wrong.
See the agent system actually produce personalized outreach live: the autonomous agents pipeline demo at Tech Week Boston.
Data interpolation is not personalization
The deepest misunderstanding in this category is the assumption that personalization is a function of how many data fields you can interpolate into a template. The buyer’s name. Their company. Their job title. Their recent press release. Their LinkedIn job change. Each field gets a placeholder, the template gets filled in, the email goes out, and the sender calls it personalized.
This is not personalization. This is data interpolation dressed up in personalization language. A human reading the result can feel the gap immediately. The sentences are about them on a surface level and not about them in any way that suggests the sender understood why they would care. Adding more fields does not close the gap. It often widens it, because each additional field is another opportunity for the message to feel scraped rather than thoughtful.
Real personalization is situational understanding. The sender knows what is happening in the buyer’s world right now, why that situation matters to a specific business problem, and how the sender’s offering connects to the moment. The fields are inputs. The understanding is the output. The fields without the understanding produce the worst-of-both-worlds artifact that is the modern AI cold email: too specific to feel generic, too generic to feel real.
When we sit down with a client to architect the outreach agent layer of their pipeline system, the first conversation is almost always about this reframe. Most teams arrive with an interpolation prompt. We rebuild it as a situational reasoning prompt. The agent writes a different email. The buyer responds at a different rate.

The four layers of real personalization
Personalization that works has four distinct layers, and a message that does all four well sounds qualitatively different from a message that does one of them. The reason most AI outreach lands flat is that it operates on only the first layer and treats the rest as decoration.
Firmographic. The basic shape of the company. Size, industry, geography, funding stage, tech stack. This is the layer that is easiest to query and produces the least interesting personalization. Apollo and Clay handle this layer well. Most cold outreach you have ever received was operating only at this layer, which is why most of it felt impersonal. Knowing that I run a 30-person agency is not personalization. It is filtering.
Role. What the person actually does inside their company. Not their job title. The functional reality of their day. A VP of Sales at a 50-person Series B has different problems than a VP of Sales at a 5,000-person enterprise, and both are different from a Chief Revenue Officer at a PE-backed portco. The agent has to reason about the role in context, not just match the title to a template. This requires the underlying ICP work and the structured ICP definition we have written about elsewhere. Without that grounding, the agent has no opinion on what the buyer actually cares about.

Moment. What is happening at this company right now that creates a reason for this person to engage. New leadership, recent funding, layoff, product launch, acquisition, technology shift, expansion into a new market. This is where the signal infrastructure earns its keep.
The intent signal architecture surfaces the trigger, UserGems or Common Room or 6sense provide the underlying detection, and the agent reasons about what the moment means for the buyer’s priorities. Without the moment layer, the message is timeless in the worst sense. Nothing about it explains why this email, why now.
Relational. The thing the buyer can verify, the connection point that says a real person did real thinking before this message arrived. A former colleague who now works at the buyer’s company. A specific blog post the buyer wrote that the sender actually read. A panel the buyer spoke on. A mutual customer who would vouch for the sender. This layer is rare in cold outreach because it is expensive to produce at human scale. It is dramatically less expensive at agent scale, which is where AI outreach has its real opportunity if it is built correctly.
A message that operates on all four layers sounds different. It is not longer. It is not more flattering. It just lands as if the sender saw the buyer as a specific person with a specific situation, instead of a row in a list with a few enrichment fields attached. The buyer can feel the difference within the first sentence.
Real personalization is not a longer email with more variables filled in. It is shorter, sharper, and unmistakably about a specific person and a specific moment.
The personalization tax the buyer pays when you get it wrong
There is a cost the buyer absorbs every time a fake-personalized email lands in their inbox, and it is worth naming because most senders never think about it. The cost is cognitive load. The buyer reads the opener, has to evaluate whether this is real, decides it is not, and feels mildly betrayed by the attempt.
Multiply that by the volume of AI-generated outreach the average B2B executive receives in 2026, and you get a buyer who has been trained to distrust personalization itself. The opener that mentions their recent funding round, their job change, their company growth, all of it now gets read with suspicion. The good faith pool has been drained by the lazy implementations. Buyers who used to give cold outreach the benefit of the doubt now scan for the pattern, find it, and archive without reading.
This is the real damage of bad AI personalization, and it falls on the next sender, not the current one. Your prospect’s tolerance for personalization has been shaped by every previous AI-generated email they received. A great cold email from a thoughtful sender now has to overcome the residue of every poorly-built attempt that arrived before it. The SDR cost model accounts for the production cost of these messages. It rarely accounts for the externality each message imposes on the market it is sent into.
The teams that figure this out treat their outbound motion as a long-term reputation game, not a short-term volume game. Every message they send either deposits trust into the buyer’s mental account or withdraws from it. Most AI-generated outreach is withdrawing from the account. The senders who deposit are competing against an increasingly fatigued audience and winning the share of reply that matters.
What an agent has to know before it writes
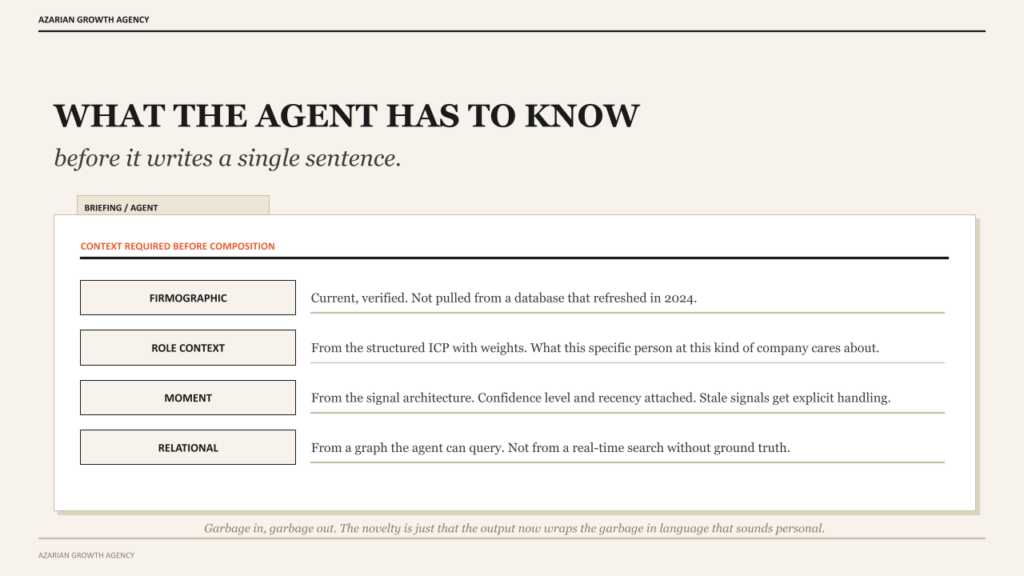
If real personalization is situational understanding, then the agent has to have access to the situation before it writes the message. This is the part where most implementations fail upstream of the prompt. The agent is asked to write a personalized email with no real context, and the prompt itself does most of the lying.
The agent needs structured information across each of the four layers before it composes anything. The firmographic data has to be current and verified, not pulled from a database that last refreshed in 2024. The role context has to come from the ICP definition with its weights and tradeoffs, so the agent can reason about what this specific person at this specific kind of company is likely to care about.
The moment has to come from the signal architecture, with confidence levels and recency attached, so the agent knows whether the trigger is fresh or stale. The relational context has to come from a graph the agent can query, not from a search the agent performs in real time without ground truth.
The orchestration layer that does this is the same one we have written about in other contexts as part of the broader autonomous GTM playbook. Claude Code for the reasoning loop, n8n for the runtime, the CRM as the source of truth for what the agent has access to about each account. The agent is not magic. It is reasoning over structured inputs it has been given by an architecture that did the hard work of assembling those inputs first.
When the inputs are wrong, the message is wrong. Garbage in, garbage out is the same principle it has always been. The novelty is just that the output now wraps the garbage in language that sounds personal, which makes the failure mode harder to spot from inside the team and easier to spot from inside the buyer’s inbox.
The prompt structure that produces non-template output

I want to talk about the actual mechanics of how the agent writes, because most teams build the prompt wrong and the failure mode is consistent across companies. The standard approach is to give the agent a template with variables and ask it to fill in the variables. The output is structurally identical to mail merge, just generated by a model instead of a string replacement function.
The approach that works is to give the agent the structured context from all four layers and ask it to reason about what message would be useful to this specific person at this specific moment. The prompt does not contain a template. It contains a brief, a voice guide, a list of constraints, and the four layers of context. The agent decides the structure of the message based on what the situation calls for. Sometimes that is a question. Sometimes it is a short observation. Sometimes it is a specific offer of help. The structure varies because the situation varies.
This is the operational difference between a workflow and an agent that Anthropic’s framework for agents articulates. A workflow runs the same template every time and varies only the inputs. An agent runs different reasoning each time and produces structurally different output as the situation requires. The buyer can feel the difference even if they cannot articulate why. The message reads as written rather than assembled.
The constraints in the prompt matter as much as the context. No more than three sentences in the opener. No flattery. No reference to features the offering does not have. No reuse of phrasings from previous messages to the same account. No closing that asks for thirty minutes on the calendar. Each constraint exists because the unconstrained agent has a default behavior that converges on the same patterns that buyers have learned to ignore. The constraints push the output back toward what an actual person paying attention would write.
The signature that tells the buyer that a machine wrote it
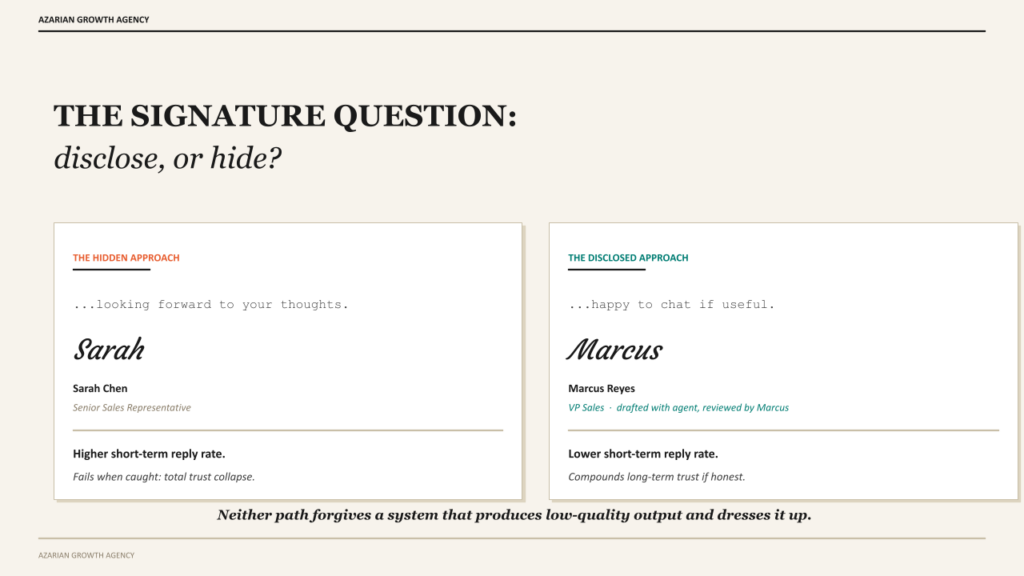
Here is a question that splits teams in this category. Should the agent’s involvement be visible in the message or hidden behind a human-looking sender?
The case for hiding it is intuitive. The buyer thinks a human wrote the message, the message lands as personal, the reply rate is higher. The case for disclosing it is harder to make but gaining ground. The disclosure tells the buyer that the company has built infrastructure that respects their time and is being honest about it. Some buyers prefer this. The category of buyer who prefers it is growing every quarter as the 6sense 2026 State of BDR Report has been tracking.
The companies experimenting with disclosure are not putting this email was written by AI in the footer. They are doing something more interesting. The sender name is a real person who reviews the agent’s outputs. The signature reflects the real person. The message itself is signed in a way that suggests human oversight of an agent-built draft. The buyer is not being deceived about the source. They are being told that a human is accountable for what got sent.
I do not have a clean answer on which approach wins long-term. The honest version is that both can work and the failure mode of each is different. The hidden approach fails when the message gets caught producing something fake-personalized, and the buyer’s trust in the entire sender brand collapses. The disclosed approach fails when the company has not actually built human oversight, and the buyer can tell the disclosure is performative. Either path requires real operational discipline. Neither path forgives a system that produces low-quality output and dresses it up.
Common failure modes and how to avoid them

Three patterns produce most of the bad AI outreach I see, and they are predictable enough to call out before you walk into them.
Stale signals presented as current. The agent references a funding round from 18 months ago as if it happened last week. The signal layer feeding the agent did not have recency weighting, or the database the signal came from refreshes too slowly. The buyer reads it, knows the timing is wrong, and the whole message loses credibility. The fix is recency thresholds on every signal the agent uses. Anything older than 90 days needs explicit handling. Anything older than a year should not be a personalization hook at all.
Hallucinated specifics. The agent writes about a specific product, partnership, or initiative that does not exist. The model invented it because the prompt asked for a specific reference and there was no real one in the context window. The buyer reads it, knows it is wrong, and the trust collapses immediately. The fix is to constrain the agent to facts from verified sources in the context, and to fail closed rather than fail open when the context does not contain a specific reference worth using. Better to write a shorter generic-feeling message than a longer fake-specific one.
Tone matching that misses the actual buyer. The agent matches the public tone of the buyer’s industry but misses the specific voice of the actual buyer. A finance executive at a hedge fund gets messaged in the casual tone of the agent’s default training, when the buyer would respond better to direct and brief. The fix is buyer-segment voice profiles in the prompt, with explicit constraints about what the tone should not be. The agent’s default is friendly and approachable. The right tone for a specific buyer is often not that.
These are mitigatable. Recency thresholds, source-grounded constraints, voice profiles by segment. None of them are exotic. All of them require treating the outreach agent as infrastructure that needs careful prompt engineering and review cycles, not as a button you press to generate emails. The build versus partner decision often turns on this point. Teams that try to build this layer themselves without the operational discipline produce the failure modes above at scale, and the failures become the company’s outreach reputation before anyone notices.
The honest answer
If you are running an AI outreach motion in 2026 and your reply rates have been declining, the diagnosis is rarely the agent and almost always the architecture above it. The agent did what it was prompted to do with the context it was given. The prompt asked for personalization, the context did not contain enough situational reality to produce real personalization, and the agent produced the artifact that fills the gap: interpolation dressed up as understanding. The buyer felt it. The buyer archived it.
The teams getting this right are not winning because they have a better model or a better tool. They are winning because they built the four layers underneath the agent before they built the agent. Structured ICP. Signal architecture.
Decision maker mapping. Relational graphs that the agent can query. The agent is the last piece, not the first piece. When the foundation is solid, the agent writes messages that sound like a person paid attention. When the foundation is missing, the same agent with the same model produces noise.
Personalization is not a feature you buy. It is a discipline you build into the architecture below the model. The teams that understand this are setting up the next decade of outbound. The teams that think a better template will save them are extending the buyer fatigue that is already breaking the category. The math is brutal in either direction.
About Azarian Growth Agency

Azarian Growth Agency is an AI native growth marketing agency working with VC backed founders, PE operating partners, and growth stage B2B leadership teams. We build full funnel growth systems anchored on agent infrastructure, with 91 agents in production across client engagements as of 2026.
Our work spans pipeline diagnostics, ICP architecture, decision maker mapping, intent signal infrastructure, outreach agent design, and the broader stack of AI content marketing, AI-driven customer insights, and generative AI for marketing. The Strategic Growth Diagnostic is the entry point for most engagements: a structured assessment of pipeline, CAC, signal infrastructure, and agent readiness, framed against the metrics PE and VC institutional buyers actually use.
Watch the live demo: Tech Week Boston autonomous agents pipeline session.

