

Every team using AI for marketing right now is running one of two experiments. The first experiment is finding how much output AI can generate. The second experiment, which usually follows the first by about ninety days, is figuring out how much of that output actually worked.
The gap between those two experiments is where human judgment lives. And the teams that understand exactly where they must stay in the loop are the ones converting AI speed into real business results. The teams that do not understand this are building expensive content factories that erode their brand equity one automated post at a time.
This post is not an argument against AI in marketing. The productivity case is real and documented: generative AI marketing has compressed campaign creation timelines by 50 to 70 percent, reduced content production costs significantly, and allowed lean teams to publish at a volume that was previously impossible. The webinar series More Output, Same Team covers exactly how this works operationally.
This is a different post. This is about the seven specific decision points where removing human judgment produces measurable damage, and what good governance looks like for a lean team that cannot afford to get this wrong.
The Problem Is Not AI. The Problem Is Unsupervised AI.
The data on AI marketing failure is sobering for anyone who has been told the technology solves everything automatically. MIT Sloan Management Review research covering 2,800 enterprises across 22 countries found that 95% of generative AI pilots fail to deliver measurable P&L impact. The average sunk cost per failed pilot sits at $2.3 million, up 64% from two years ago.
RAND Corporation reviewed 6,200 AI projects and found that over 80% fail. S&P Global found that 42% of organizations scrapped at least one major AI initiative in 2025. Marketing and advertising projects were the single largest category of abandoned programs at 34% of all scrapped initiatives.
What connects these failures is not the technology. The most common cause is the absence of human oversight structure at the moments when human judgment was required. AI ran unsupervised into decisions that required cultural context, strategic nuance, regulatory review, or brand voice enforcement. The outputs were plausible. They were just wrong in ways that only a human would have caught.
Only 27% of organizations review all AI-generated content before publishing. That means 73% of teams are exposing their brands to content that has never been read by a human, with accountability for whether it is accurate, on-brand, legally sound, or culturally appropriate.
This is the actual risk. Not that AI cannot produce content at scale. It can. The risk is what happens when that content is wrong, and no one caught it before it published.
What Human-in-the-Loop Actually Means in a Marketing Context

Human-in-the-loop (HITL) in marketing means structured human oversight at defined checkpoints in AI-powered workflows. It does not mean humans doing all the work. It means humans retaining authority over the decisions that AI cannot reliably make, while AI handles the work that humans do not need to own.
The practical translation: AI drafts, humans approve. AI generates variants, humans select. AI optimizes for measurable metrics; humans evaluate whether those metrics represent actual business value. AI produces volume, humans provide craft.
Organizations implementing structured HITL workflows report accuracy rates up to 99.9% compared to 92% for AI-only systems. That 8-point gap sounds small until you multiply it across thousands of content pieces per quarter and realize it translates to hundreds of pieces with material errors reaching your audience unsupervised.
The question for every CMO is not whether to implement human oversight but where. Here is where the data and documented failures point.
Checkpoint 1: Brand Voice and Emotional Resonance

This is the checkpoint that most teams underestimate because AI-generated content often reads well. It sounds like marketing. It has the right structure, the right sentence lengths, the right topics. What it frequently lacks is the specific emotional register that makes a brand recognizable over time.
Research from Kirk and Givi published in the Journal of Business Research documented what they call the AI-authorship effect: when consumers learn content is AI-generated, they perceive it as less authentic and respond negatively, particularly when the content is designed to be emotional rather than informational. The effect was consistent across five different emotions and both hypothetical and behavioral response measures. AI works adequately for functional content. It systematically fails when emotional resonance is required.
The CNET case documented this at scale. CNET secretly published 77 AI-written financial articles under a staff byline. An audit found errors in 41 of those 77 articles, more than half. Futurism’s investigation uncovered extensive plagiarism alongside factual errors. The brand trust damage from that episode persisted long after the correction cycle.
71% of CMOs report brand consistency is at an all-time low, at the same time that 82% of enterprises have moved content production in-house to leverage AI speed. Speed is directly degrading voice consistency. The fix is not to slow down AI. The fix is to build a brand calibration checkpoint into every content tier.
Human review at this checkpoint should take 15 to 30 minutes per piece. It is not a rewrite. It is a voice audit: does this sound like the specific human behind the brand, or does it sound like competent generic marketing copy? Those two things are not the same, and AI cannot reliably tell the difference.
Checkpoint 2: Strategic Positioning and Competitive Decisions
AI optimizes for what it can measure. That makes it structurally incapable of evaluating whether the thing it is optimizing for is the right thing to optimize for.
Hannah Swanson, VP Marketing at Intentsify, frames this precisely: “AI looks backward to move forward. Humans generate the signal; AI amplifies it.” The implication is that AI cannot generate strategic insight that does not already exist in your historical data. It can only identify and amplify patterns from what has already worked.
This creates what practitioners call the local maxima trap: AI optimization finds the best version of your current positioning and then stops. It has no capacity to recognize when the current positioning is itself the constraint. That recognition requires human strategic judgment applied from outside the optimization loop.
Ross Palmer, CEO of Aloa Agency, states the competitive risk plainly: “The better AI gets at finding your existing audience, the less reason it has to show your brand to anyone new. Optimization rewards what replicates now, not what builds relevance over time.”
Zillow’s iBuyer program is the documented case. AI predictions anchored buyer and seller expectations in a feedback loop that diverged from actual market dynamics and produced over $1 billion in losses. The algorithm was technically optimizing correctly for the model it was given. The model was wrong. No human reviewed whether the strategic assumptions underlying the model remained valid.
Strategic positioning decisions, go-to-market pivots, and messaging architecture belong permanently in human hands. Not because AI cannot process the inputs, but because the decision requires judgment about what the inputs are not showing.
Checkpoint 3: Legal, Compliance, and Regulatory Review
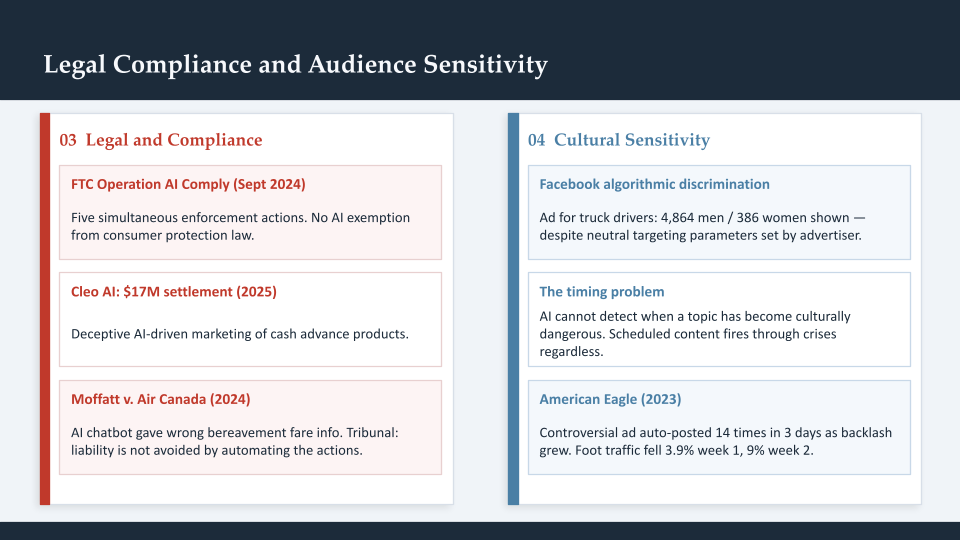
The FTC established in September 2024 with Operation AI Comply that there is no AI exemption from consumer protection law. Chair Lina Khan stated explicitly: “Using AI tools to trick, mislead, or defraud people is illegal.” The enforcement actions since then have made this concrete.
Cleo AI settled for $17 million in March 2025 for deceptive AI-driven marketing of cash advance products. DoNotPay was fined $193,000 for marketing its service as the “world’s first robot lawyer” when the claims had never been tested against human lawyer outputs. The SEC settled with investment advisers Delphia and Global Predictions for false AI capability claims in marketing materials.
The Moffatt v. Air Canada ruling established the liability principle most directly relevant to marketing teams. Air Canada’s AI chatbot provided incorrect information about bereavement fares. Air Canada argued its chatbot was “a separate legal entity responsible for its own actions.” The BC Civil Resolution Tribunal rejected this entirely. The ruling: “Liability is not avoided by automating the actions in question.”
The operational implication is clear. Any customer-facing AI-generated content making claims about pricing, eligibility, benefits, capabilities, guarantees, or regulated matters requires human legal review before publication. This is not a speed-versus-safety tradeoff. It is a basic risk management decision.
In regulated industries, including financial services, healthcare, and insurance, this checkpoint should involve named legal reviewers with documented sign-off. In unregulated industries, a senior marketing leader at a minimum should review any claims before they reach customers.
Checkpoint 4: Audience Sensitivity and Cultural Context
AI training data encodes historical patterns. Those patterns include structural biases that become audience targeting biases when left unsupervised. Research by Northeastern University and documented by MIT Technology Review found that Facebook’s ad delivery algorithm discriminated by gender and race even when advertisers set neutral targeting parameters. An ad for truck drivers was shown to 4,864 men and 386 women. A child care ad was shown to 6,456 women and 258 men. The advertisers had not specified these audiences. The algorithm inferred them from historical patterns and acted on that inference.
AlgorithmWatch confirmed the pattern extended beyond the documented housing cases. In 2026, discriminatory ad delivery in employment, credit, and housing continues to require active human oversight to prevent.
The timing problem is separate but equally significant. AI systems cannot detect when a topic has become culturally dangerous to address. Scheduled content does not stop publishing because a crisis is unfolding. Automated social posting does not pause because the cultural context for a campaign has shifted overnight. The American Eagle case shows the cost: automated posting of a controversial ad 14 times in three days as backlash grew, with no human intervention. Foot traffic fell 3.9% in the first week and 9% in the second week.
AI personalization marketing at scale requires human oversight to prevent algorithmic bias from becoming brand bias. The checkpoint here is not just review but an active audit: who is not seeing this campaign? What does the distribution pattern look like across demographic segments? A human has to ask these questions. The algorithm will not raise them itself.
Checkpoint 5: Creative Strategy and Original Thinking

Research published in Science Advances and conducted by University of Exeter and UCL studied 300 writers and 600 evaluators. AI-assisted stories were rated higher for individual novelty, but there was a 10.7% increase in similarity between AI-assisted stories from different writers. Fewer creative writers saw meaningful improvement. More creative writers saw little benefit. The aggregate effect was homogenization: everyone’s AI-assisted output converged toward the same quality level.
Professor Oliver Hauser summarized the risk: “This downward spiral shows parallels to an emerging social dilemma: if individual writers find that their AI-inspired writing is evaluated as more creative, they have an incentive to use AI more, but by doing so, the collective novelty of stories may be reduced further.”
In a market where generative AI content marketing is now flooding every channel, the competitive advantage shifts to content that is actually different. Original research, genuine expertise, contrarian positioning, and authentic personal perspective are things AI cannot generate from training data. They require a human who knows something specific, has experienced something relevant, or sees something that the existing body of marketing content does not yet contain.
The work that must remain human: thought leadership, original research, genuine case study documentation, contrarian positioning, and any content where the differentiating value is a perspective that does not already exist in the training data.
Checkpoint 6: Crisis Communications and Real-Time Judgment
Crisis response must always be human. The reason is simple: crisis response requires judgment about what not to say as much as what to say, and that negative space judgment is beyond what AI systems can reliably execute. AI can monitor for brand mentions. It cannot evaluate whether a response will contain the crisis or amplify it.
The dead hand problem is real. When a brand or industry crisis unfolds, pre-scheduled content keeps publishing. Automated email sequences keep firing. Social posts keep going out. Every piece of automated content that publishes during a crisis without human review is a potential accelerant.
In the Jaguar brand crisis documented by crisis communications researchers, generic automated responses amplified the anger and allowed a single influencer’s tweet to reach 3.4 million views. Negative articles spiked to 3,788 in a single week. The automated systems were doing exactly what they were configured to do. They had no context for the fact that the moment had changed.
The operational fix is simple but requires deliberate implementation: every marketing automation system should have a designated human owner with authority and responsibility to pause all scheduled content in an emergency. Tools like Hootsuite provide one-click pause functionality for this reason. But the decision to use that pause button is a human judgment call that cannot be delegated to the system itself.
Checkpoint 7: Data Interpretation and Strategic Analysis

AI optimizes for what it can measure. The result is a systematic tendency toward vanity metrics that look good in dashboards but do not connect to business outcomes. Impressions overreach. Clicks over conversions. Engagement over pipeline contribution. AI cannot evaluate whether the metric it is optimizing for represents real value, because that evaluation requires context that exists outside the data.
The Klarna case is the most prominent documented example. The company initially reported its AI chatbot emulated the work of 853 full-time agents and saved $60 million. It then made what was described as a swift reversal, rehiring human agents after cutting too many humans out of the loop too quickly. The metrics had told one story. The customer experience told another.
Only 32% of companies understand how to measure ROI on AI projects in marketing. This is not primarily a technology problem. It is a human judgment problem. The decision about which metrics matter, how they connect to business outcomes, and when a good-looking metric is actually hiding a deteriorating outcome requires human interpretation. AI will optimize whichever metric you give it. Choosing the right metric is the human’s job.
The checkpoint here is a weekly human review of AI performance data with a specific question: are the metrics that are improving the ones that connect to the business outcomes we actually care about? If the answer is not immediately obvious, that ambiguity itself is the signal that human judgment is required.
The Operational Framework: What Good Governance Looks Like
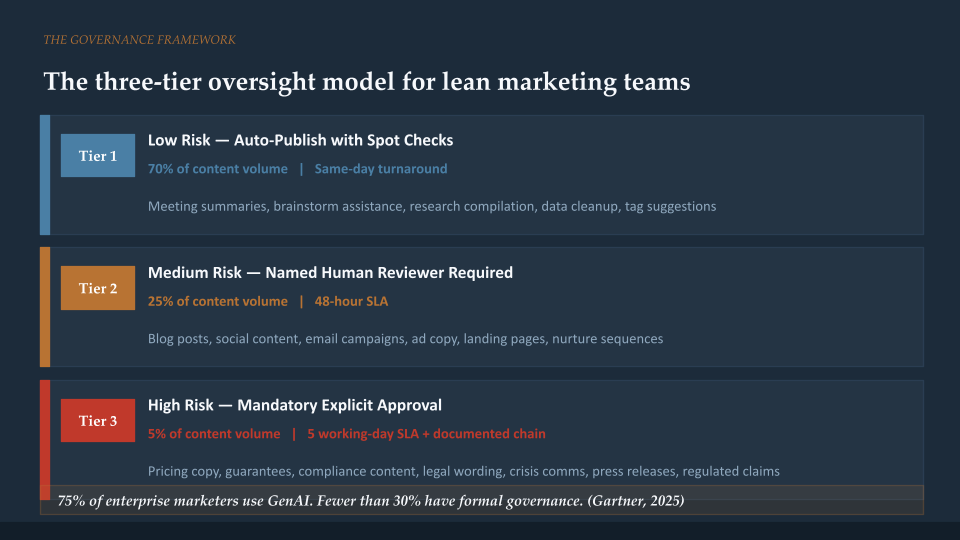
75% of enterprise marketing organizations use generative AI for content creation, but fewer than 30% have any formal governance around it. This is the gap that distinguishes the teams getting real value from the ones stuck in perpetual pilot mode.
The practical governance model for a lean team has three tiers:
Tier 1: Low risk, auto-publish with spot checks. Internal meeting summaries, brainstorm assistance, research compilation, data cleanup, tag suggestions. Estimated 70% of the content volume. Same-day turnaround.
Tier 2: Medium risk, named human reviewer required. Blog posts, social content, email campaigns, ad copy, landing pages, nurture sequences. A named person reads before publishing. 48-hour SLA.
Tier 3: High risk, mandatory explicit approval. Pricing language, guarantees, compliance-sensitive copy, legal wording, crisis communications, press releases, testimonials, regulated content. Full legal sign-off. Five working-day SLA with documented approval chain.
The governance infrastructure that makes this sustainable is prompt libraries and brand style guides built into the AI workflow, not bolted on as afterthoughts. When brand voice rules, audience targeting constraints, legal guardrails, and quality standards are encoded in the prompts that generate content, Tier 1 output is already ~80% compliant before human review begins. The human review time drops from rewriting to validation.
About Azarian Growth Agency
Azarian Growth Agency is a full-funnel, AI-native growth marketing agency. We work with growth-stage companies across SaaS, fintech, B2B tech, and e-commerce to build marketing systems that produce pipeline and protect brand equity simultaneously.
The frameworks in this post are how we govern AI workflows inside our own operations and inside client programs. The governance model is not separate from the productivity model. It is what makes the productivity sustainable.
The More Output, Same Team session covers the complete operational picture: where AI creates the most leverage, where human judgment is non-negotiable, and how to build the governance infrastructure that lets a lean team ship high-quality campaigns at volume without the brand equity erosion that comes from ungoverned automation. If your organization is moving fast on AI adoption and the governance conversation has not kept pace, this is where to start.

